
Magazin robots.txt: Alles, was ein SEO wissen muss
Die kleine robots.txt-Datei spielt in der Suchmaschinen-Optimierung eine große Rolle, da sie das Crawling Ihrer Website und letztlich auch die Indexierung steuert. Und ohne Crawling keine Indexierung, keine Rankings und keine organischen Klicks.
Im Folgenden haben wir die wichtigsten Informationen zur robots.txt für Sie zusammengefasst. Diese Daten beziehen sich primär auf Google-Crawler, jedoch werden die beschriebenen Funktionen in der Regel auch von Bing und anderen großen Suchmaschinen unterstützt.

Grundlagen: Was ist eine robots.txt?
Die robots.txt ist eine einfache Textdatei, die einfach per normalem Texteditor erstellt werden kann. Sie dient der Steuerung von Webcrawler-Zugriffen auf Ihre Website, wie dem Googlebot, dem Bingbot oder auch dem Crawler von ChatGPT. Gutartige Crawler oder Programme werden sich an Ihre Anweisungen halten, ein Schutz gegen unbefugten Zugriff stellt die robots.txt allerdings nicht dar.
Anwendung findet die robots.txt immer dann, wenn Sie verhindern möchten, dass bestimmte Teile Ihrer Website von Suchmaschinen gecrawlt und letztlich indexiert werden und so in den Suchergebnissen auftauchen sollen. Dies kann nützlich sein, um irrelevante Inhalte vor Suchmaschinen zu verbergen. So lenken Sie den Fokus der Suchmaschinen auf die für Sie bzw. Ihre Nutzer:innen relevanten Inhalte. Zu den für die (Google-)Suche irrelevanten Inhalten können unter anderem diese zählen:
Backend-Bereich des CMS (ist idealerweise noch durch weitere Maßnahmen geschützt)
Warenkorb oder Checkout-Seiten
temporäre Verzeichnisse und Dateien
reine Formularseiten
Suchergebnisseiten Ihrer Website-Suche
jede sonstige Art von URL oder Dateityp, die Sie ausdrücklich aus dem Suchindex von Suchmaschinen ausschließen möchten
In der Datei kann auch angegeben werden, wo sich Ihre XML-Sitemaps befinden, da diese in der Regel nicht über die reguläre interne Verlinkung erreichbar sind. So können Crawler diese ebenfalls wichtige Datei(en) einfacher auffinden.
Format und Speichertort der robots.txt
Der Aufruf jeder robots.txt ist denkbar einfach. Geben Sie einfach die Domain gefolgt von /robots.txt ein und Sie erhalten Zugriff auf jede im Netz verfügbare robots.txt. z. B. www.mindshape.de/robots.txt
Das liegt daran, dass die fertige Datei immer im root-Verzeichnis der Domain abgelegt werden muss, da Suchmaschinen diese Textdatei nur unter dem Pfad ihre-domain.de/robots.txt erwarten. Ein abweichender Speicherort ist nicht möglich.
Weitere Regeln für eine robots.txt
Der Dateiname muss immer vollständig klein geschrieben werden. Heißt die Datei „Robots.txt“ haben die darin enthaltenen Anweisungen keine Auswirkung.
Eine robots.txt-Datei gilt nur für genau ein Protokoll, einen Host und einen Server-Port. Das heißt z. B. das für Sub-Domains jeweils eine eigene robots.txt erstellt werden muss.
Die robots.txt muss UTF8-codiert sein. Zeichen, die nicht zum den UTF8-Zeichen gehören werden von Google oder andern ggf. ignoriert.
Um die Textdatei selbst auf dem Webserver ablegen oder ändern zu können, benötigen Sie Zugriffsrechte mit Schreibrecht auf den jeweiligen Webserver. Häufig geschieht der Zugriff via FTP. Im Zweifel hilft hier der Webhoster weiter.
Aufbau der robots.txt: Anweisungen für Bots eintragen
Die robots.txt besteht in der Regel ganz grundlegend aus folgenden Teilen:
Angaben darüber welche Pfade, Verzeichnisse oder Dateitypen von Crawlern nicht besucht werden dürfen
Alternativ kann grundsätzlich auch der Zugriff auf alles verboten, dann aber gezielt bestimmte Bereiche geöffnet werden. Das hat aber das Risiko das wichtige Bereiche oder Bot-Programme beim Whitelisting vergessen werden.Angabe von einen oder mehreren Pfaden zu XML-Sitemaps
Optional können auch noch Kommentare hinterlassen werden, welche den eigenen Mitarbeiter:innen noch Mal die Abschnitte erklären. Ein Art Dokumentation also. Kommentare Beginnen immer mit dem Raute-Symbol (#).
Einfaches Beispiel einer robots.txt-Datei:
#Kommentar (in eigener Zeile), beginnt mit einer Raute
User-agent: *
Disallow: /login
Disallow: /*pdf$
Sitemap: https://www. mindshape.de/sitemap.xml In diesem Beispiel wird in der ersten Zeile ein Kommentar eingefügt. Mit der Angabe „User-agent: *“ teilen wir mit, dass die folgenden Befehle für alle Bots gelten soll. Das Sternchen ist hier eine Wildcard, die alle möglichen Ausprägungen repräsentiert. Anschließend wird angegeben, dass URLs mit dem Pfadsegment "/login" nicht gecrawlt werden dürfen. Ebenso dürfen alle URLs, die auf .pdf enden (das $-Zeichen zeigt an, dass danach keine weiteren Zeichen folgen dürfen), nicht gecrawlt werden. Zum Schluss wird der Pfad zur XML-Sitemap angegeben.
Wichtig: Jede Anweisung muss in eine neue Zeile geschrieben werden.
Syntax der robots.txt
| Eingabe | Erklärung | Beispiel |
|---|---|---|
| # | Kommentarzeile | # robots.txt für mindshape.de |
| * | Wildcard. Nutzbar für User-agents und URL-Pfade. Hier werden alle URLs mit einem ? vom Crawling ausgeschlossen. | Disallow: /*? |
| $ | Kennzeichnet das Pfadende. In diesem Beispiel werden alle URLs mit dem Ende „.pdf“ vom Crawling ausgeschlossen. | Disallow: /*.pdf$ |
| User-agent: | Angesprochene(r) Crawler. Hier wird der Bot mit dem Namen Googlebot adressiert (mehrere gleichzeitig untereinander aufgeführt funktionieren) | User-agent: Googlebot |
| Allow: | Erlaube Besuch. Es wird erlaubt, die angegeben URL zu crawlen. (Die Angabe „Allow“ ist nur dann erforderlich, wenn eine Ausnahme von Ausschlüssen definiert werden soll und daher eine explizite Erlaubnis erforderlich ist.) | Allow: /nur-diese-datei.html |
| Disallow: | Verbiete Besuch. Es wird nicht erlaubt, die angegebene URL zu crawlen. | Disallow: /nicht-das-hier.html |
| Sitemap: | Angabe des Pfades, unter dem Sitemap(s) zu finden sind. | Sitemap: https: //www.mindshape.de/sitemap.xml |
| Crawl-delay: | Verzögerung in Sekunden zwischen zwei Abrufen. Wird von Google nicht befolgt. Tipp: Weglassen. | Crawl-Delay: 120 |
| Noindex: | Entfernung angegebener Dateien aus dem Index (offiziell nicht unterstützt) | noindex:/testseite.html |
Beispiele aus der SEO-Praxis für Ihre robots.txt-Datei
| Beispiel | Angabe in der robots.txt |
|---|---|
| Crawling von Suchmaschinen komplett sperren | User-agent:* Disallow: / |
| Aufruf nur einem speziellen Crawler erlauben | User-agent: Googlebot Disallow: (Hinweis: alternativ auch „Allow: /“ möglich) User-agent: * (für alle außer dem eben angesprochenen Googlebot) Disallow: / |
| Eine spezielle URL sperren | User-agent: * Disallow: /diese-url-darf-nicht-gecrawlt-werden |
| Ein bestimmtes Verzeichnis sperren | User-agent: Disallow: /test-verzeichnis/ |
| Alle URLs mit GET-Parametern sperren | User-agent: * Disallow: /*? |
| Ausschluss bestimmter Dateien-Typen (z.B. PDFs) | User-agent:* Disallow: /*.pdf$ |
| Ein bestimmtes Bild für die Google-Bildersuche sperren | User-agent: Googlebot-Image Disallow: /bilder/mitarbeiter-a.jpg |
Eine aktuelle Übersicht über alle von Google verwendeten Crawlern bzw. User-Agents findet Sie hier: developers.google.com/search/docs/crawling-indexing/overview-google-crawlers.
Indexiert, obwohl durch robots.txt-Datei blockiert
Grundsätzlich halten sich Google und Co., also die vermeidlichen Good Guys des www, an die Anweisung in Ihrer robots.txt. Dennoch kann es vorkommen, dass Suchmaschinen die Inhalte dennoch in der Suche auflisten. Doch wie kann das sein?
Google und andere sehen die Direktiven in robots.txt mehr als Empfehlung den als harte Anweisung. Das gilt insbesondere dann, wenn ihre Inhalte stark verlinkt sind. Das kann auf der eigenen Website passieren oder auch durch Backlinks. In dem Fall kann Google davon ausgehen, dass der Inhalte trotz Crawl-Sperre relevant ist und nimmt die URL in den Index mit auf.
Sofern Sie einen kostenlosen Google Search Console-Account angelegt haben (unbedingt zu empfehlen), finden Sie im Falle das Ihre Website betroffen ist unter „Seiten“ einen Bericht Namens „Indexiert, obwohl durch robots.txt-Datei blockiert“. Dort werden URLs aufgelistet, die von diesem Problem betroffen sind.
Hilft die robots.txt gegen doppelte Inhalte (Duplicate Content)
Grundsätzlich können Befehle in der robots.txt helfen, URLs mit doppelten Inhalten vom Crawling auszusperren. Allerdings ist das immer nur eine Art Notnagel, wenn es keine andere Möglichkeit gibt. Denn wie eben erwähnt gibt es keine Garantie, dass diese Inhalte nicht doch indexiert werden.
Beispiel:
Angenommen, eine Website hat zwei URLs, die denselben Artikel anzeigen, aber eine der URLs enthält Parameter für eine Variante und eine Farbe. Die Varianten sind sich jedoch sehr ähnlich und sollten daher nicht von Google gecrawlt werden.
- "https://www.example.com/article"
- "https://www.example.com/article?variant=123&color=blue"
Um Suchmaschinen daran zu hindern, die URL mit den Parametern zu crawlen, könnten Sie folgende Anweisung in die robots.txt-Datei aufnehmen:
User-agent: *
Disallow: /*?variant=*
Disallow: /*&color=*
Ist die Anweisung in der robots.txt mit einem noindex gleich zu setzen?
Um es kurz zu machen: Nein! Zwar gab es bis 2019 die Möglichkeit, auch ein noindex in der robots.txt zu verwenden, doch wird dieses nie offiziell kommunizierte Feature von Google inzwischen nicht mehr unterstützt. Andere Suchmaschinen haben diesen Befehl nie beachtet. Zudem halten sich Google und Co. wie oben beschrieben nicht immer an die Anweisungen der robots.txt. Um also absolut sicher zu gehen, verwenden Sie bitte die noindex-Angaben in den HTML-Meta-Angaben oder via X-Robots-Tag im HTTP-Header. Diese beiden Direktiven werden in jedem Fall beachtet.
Die Inhalte sind bereits indexiert? Das können Sie unternehmen!
Wenn Inhalte, die eigentlich nicht in den Suchindex sollten, bereits indexiert sind, können die robots.txt-Angaben nicht mehr helfen. Im Gegenteil, sie würden sogar ein Entfernen aus dem Index blockieren, da Google und Co. notwendige noindex-Angaben nicht aufrufen können. Sie verhindert ja das erneute Crawling.
Gehen Sie in einem solchen Falle wie folgt vor:
Fügen Sie allen URLs, die aus dem Suchindex entfernen werden sollen, eine noindex hinzu (Meta-Angaben im HTML-Body oder im HTTP-Header).
Falls Sie die URLs in Panik in der robots.txt blockiert haben, heben Sie die Crawl-Sperre wieder auf.
Stoßen Sie ggf. das erneute Crawling in der Google Search Console über das Menü „URL-Prüfung“ manuell an. Allerdings kann hier nur jede URL einzeln zur Indexierung (bzw. zum erneuten Crawling) eingereicht werden. Alternativ können Sie eine extra XML-Sitemap mit einer Liste aller URLs, die erneut geprüft werden sollen, einreichen. Das kann den Vorgang etwas beschleunigen.
Sofern die URLs sofort aus den Suchergebnissen ausgeblendet werden sollen (Achtung, Ausblenden heißt nicht, dass die URLs nicht noch im Index sind!), können Sie ebenfalls in der GSC unter dem Menüpunkt „Entfernen“ URLs ausblenden lassen. Der Name der Funktion ist in dem Fall etwas irrführend. Die URLs werden dann bis zu etwa sechs Monate aus den Google-Suchergebnissen ausgeblendet.
Prüfe Sie regelmäßig, ob die zu de-indexierenden URLs aus dem Index entfernt wurden. Sehr nützlich ist in dem Fall die in Punkt drei angesprochene extra XML-Sitemap. Einmal bei Google eingereicht, können Sie in der GSC unter dem Punkt Sitemaps genau diese Sitemap auf den Indexierungszustand hin überprüfen.
Sobald die URLs tatsächlich de-indexiert wurden, können diese wieder mittels robots.txt blockiert werden.
Kann die robots.txt bei Crawl Budget-Problemen helfen?
Ja, Sie können mit der robots.txt Ihr Crawl-Budget optimieren. Indem Sie bestimmte Seiten (und Unterseiten) oder Verzeichnisse vom Crawling ausschließen. ABER, dieses Vorgehen ist allerdings erst bei Domains mit deutlich mehr als 50.000 URLs relevant und sollte daher für die meisten Websites keine Rolle spielen. Grundsätzlich kann es aber hilfreich sein, die Crawler nur auf Search-relevanten Seiten agieren zu lassen. Sofern Sie sehr viele URLs haben, sollten Sie also Gedanken dazu machen, da es sonst dazu kommen könnte das wichtige Inhalte nicht erfasst oder nicht schnell genug aktualisiert werden.
Muss die robots.txt bei Google eingereicht werden?
Nein, Sie müssen die robots.tx.t nicht einreichen. Das geht streng genommen auch nicht. Im Robots-Exlusion-Standard-Protokoll ist klar geregelt, wo diese Textdatei zu finden ist, wie sie zu heißen hat und Suchmaschinen schauen selbstständig und standardmäßig nach den Inhalten der Datei.
Typische robots.txt-Fehler
| Fehler | Erklärung & Beispiel |
|---|---|
| Anstatt einem Verzeichnis werden versehentlich auch weitere Pfad-Bestandteile gesperrt („/“ vergessen) | Soll ein Verzeichnis und dessen Unterseiten gesperrt werden, muss an das Slash am Ende des Verzeichnisnamens gedacht werden. „Disallow: /temp“ sperrt nicht nur /temp/, sondern auch /temperatur-messer oder /temperatur-messer.html Falsch: Disallow: /temp |
| Neben Parametern werden versehentlich andere URLs ausgeschlossen | Mit der Angabe „Disallow: /*sid“ sollen URLs mit Session-IDs wie „https://www.example.com/cart?sid=12345“ gesperrt werden. Jedoch muss immer überprüft werden, ob wirklich nur die gemeinten URLs ausgeschlossen werden. Denn der Befehl sperrt in diesem Beispiel auch Seiten wie „https://www.example.com/inside-page“ Falsch: Disallow: /*sid |
| Robots.txt statt robots.txt | Der Crawler ist case-sensitive, daher ist die robots.txt eine andere Datei als die Robots.txt. Wenn Ihre Datei nicht robots.txt heißt wird sie nicht gefunden werden. |
| Groß- und Kleinschreibung wird nicht beachtet | Wie zuvor erwähnt, ist .PDF für den Crawler etwas anderes als .pdf. Um solche Fehler im Vorhinein zu vermeiden, sollte Sie immer alle URLs Ihrer Website und deren Bestandteile klein schreiben. Ohne Ausnahme. |
| Die Angabe „Disallow: /“ wurde vor dem Live-Gang vergessen zu entfernen | Diese Angabe verhindert, ohne definierte Ausnahmen, jegliches Crawling und Indexerung. Ihre Website wird keine Rankings erzielen. |
| Es sollen mehrere Verzeichnisse mit der Angabe „Disallow: /temp/ /admin/“ ausgeschlossen werden | In diesem Beispiel sollten zwei Verzeichnisse gesperrt werden. Der Crawler aber liest alles hinter einem Disallow als einen einzelnen Pfad – dementsprechend funktioniert die Angabe nicht. Falsch: Disallow: /temp/ /admin/ |
| Geheime, nicht öffentliche Verzeichnisse und Dateien werden angegeben | „Disallow: /redesign/“ teilt dem Wettbewerb zuverlässig mit, wo sie zuerst schauen sollen. Sofern das nicht möglich ist, verwenden Sie das Robots Meta-Tag mit der Anweisung „noindex, nofollow“. So wird Google die Arbeit am Redesign nicht vorzeigtig indexieren, aber Sie verraten niemanden, dass diese Inhalte schon in Arbeit sind. |
| robots.txt von anderer Domain ohne Anpassung kopieren | In der Folge stimmt meistens die Angabe der Sitemap nicht. Und im schlimmsten Fall sperren Sie versehentlich Verzeichnisse oder Pfade, die Sie gar nicht sperren wollten. |
| Bei einem Domain-Wechsel wird auch die URL der alten robots.txt weitergeleitet | Wenn Sie bei einem Domain-Wechsel die URL alte-domain.de/robots.txt auf neu-domain.de/robots.txt weiterleiten, dann gelten die Angaben der neuen robots.txt rekursiv auch für alle Verzeichnisse und Pfade der alten Domain. Das kann dazu führen, dass Google andere Weiterleitungen nicht erkennt, wenn Ausschlüsse das Auslesen der Weiterleitung durch Bots unterbinden. In der Folge werden Rankings nicht auf die neue Domain übertragen, sondern gehen verloren. |
| Ausgeschlossene Seiten haben Backlinks oder relevante Rankings | Hier kann es zu zwei Effekten kommen. Entweder wird die Seite dennoch auf Grund der Backlinks indexiert, da Google diese für relevant hält. Oder Google entscheidet sich Ihrer Anweisung Folge zu leisten und die Rankings gehen verloren. |
| genereller Ausschluss von Bildern | Über die Google-Bildersuche kann eine Menge qualifizierter Traffic kommen. Zudem ist die Vorschau, auch in der Universal-Search, entsprechend beeinträchtigt, wenn Google die Bilder nicht indexieren darf. Achten Sie auch darauf, dass Bilder oder andere Ressourcen, die von einer Subdomain geladen werden, nicht ebenfalls über einen kompletten Ausschluss der Sub-Domain blockiert werden. In dem Fall müssen Sie die Datei unter subdomain.rootdomain.de/robots.txt kontrollieren. |
| Ausschluss über die robots.txt als Allheilmittel | Eine Sperrung über die robots.txt sollte immer als das letzte Mittel angesehen werden, denn wie die Punkte hier auf der Liste zeigen, kann es viele Probleme geben. Viel zuverlässiger hält das Robots-Meta-Tag mit der Einstellung „noindex“ von der Indexierung ab. Noch dazu werden gleichzeitig alle Links der Seite weiter verfolgt, wenn Sie denn wollen. Auch das Meta-Tag „Canonical“ kann dazu dienen, bei doppelten Inhalten auf den zu indexierenden Inhalt zu weisen. Beide Angaben haben bei einem Ausschluss in der robots.txt keine Wirkung! |
| Anweisungen betreffen Subdomains | Jede Subdomain benötigt eine eigene robots.txt. Anweisungen von der robots.txt einer anderen (Sub-) Domain gelten nicht. |
| Robots.txt ist nicht im obersten Verzeichnis (root) gespeichert | Ist die Datei in einem anderen Verzeichnis gespeichert, findet der Crawler die Datei nicht und geht davon aus, dass keine Einschränkungen bestehen. Falsch: example.com/verzeichnis/robots.txt |
| Anweisung an verschiedene User-Agents sind nicht getrennt | Wie bei Verzeichnissen oder Pfaden muss jeder User-Agent separat angesprochen werden. |
| User-Agent:* Allow: / | An sich kein Fehler, aber überflüssig. Dieser Befehl wird von den Crawlern per Default angenommen, wenn keine gegenteiligen Befehle gefunden werden. |
| Pfadende oder Anfang werden nicht gekennzeichnet | Das Pfadende wird nicht sauber gezeichnet und damit werden versehentlich auch andere Pfade gesperrt. Beispiel: Mit der Eingabe Disallow: /*pdf sollten alle PDFs gesperrt werden. Jedoch wird jeglicher Pfad ausgeschlossen, der pdf enthält (z. B. auch example.com/documents/pdf-guide). Falsch: Disallow: /*pdf Der Punkt vor dem String „pdf“ stellt sicher, dass eben dieser Punkt vor dem Dateityp stehen muss. Das $ am Ende stellt sicher, dass hier nicht mehr folgen darf. |
| CSS- oder JavaScript werden generell von der Indexierung ausgeschlossen | In gewissen Fällen kann es zwar Sinn machen, Funktionen zu sperren, bei einem generellen Ausschluss kann der Ausschluss jedoch zu schlechteren Rankings führen. Denn Google benötigt Zugriff auf diese Dateien, um Ihre Website sauber zu rendern. Fehlen diese Dateien, ist die Darstellung oft unsauber oder Inhalte fehlen ganz. |
So testen Sie Ihre robots.txt
Da die Einträge in Ihre robots.txt eine große Auswirkung haben können, sollten Sie diese unbedingt vor dem Upload auf ein Live-System testen. Da gibt es unterschiedlichste Möglichkeiten.
robots.txt-Tester der Google Search Console
Google selbst bietet eine recht versteckte und eher rudimentäre Funktion zum Testen an. Diese finden Sie in der GSC unter „Einstellungen“ > „robots.txt“.
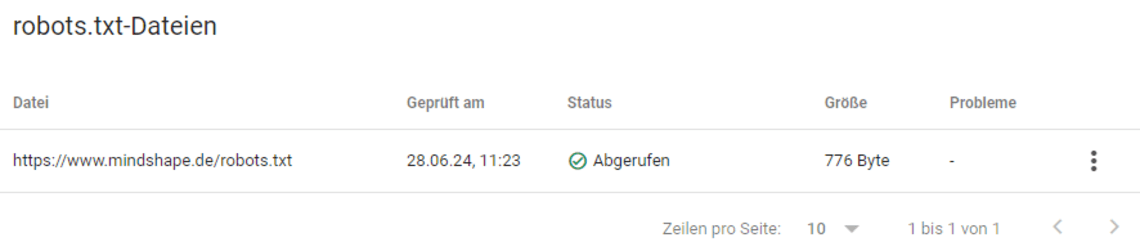
Dort können Sie zum einen sehen, ob Google Ihre robots.txt gefunden und erkannt hat, zum anderen werden dort Verarbeitungsfehler aufgezeigt. Eine Debugging-Funktion, die es in der Vergangenheit einmal gab, existiert leider nicht mehr.
Praktisch sind hingegen die Möglichkeiten, alte Versionen der robots.txt einzusehen und das Re-Crawling der Datei zu forcieren. Letzteres kann praktisch sein, wenn Sie Aktualisierungen vorgenommen haben und diese möglichst schnell von Google verarbeitet werden sollen. Klicken Sie dafür auf die drei Punkte in der Übersicht der Dateien und dann auf den entsprechenden Eintrag.
Näheres zu dem Tool von Google finden Sie auch hier: https://support.google.com/webmasters/answer/6062598?hl=de
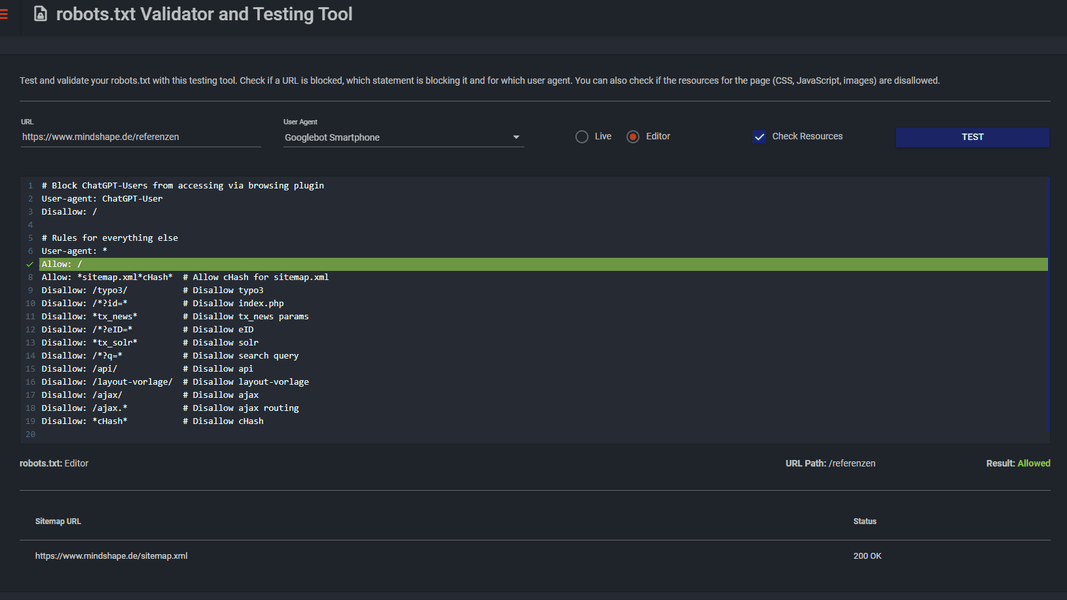
robots.txt-Tester von Merkle
Merkle bietet unter technicalseo.com/tools/ eine ganze Reihe von praktischen Tools an, unter anderem den robots.txt Tester der auch eine Debugging-Funktion bietet. Hier können Sie sowohl den Code von der Live-Website als auch einen im Editor eingefügten Code testen.
Weiterhin bietet der Tester die Möglichkeit, einen User-Agent auszuwählen, um verschiedene Szenarien durchzuspielen oder bei dem Test der Live-Datei auch verlinkte Ressourcen hinsichtlich einer Blockade zu prüfen.
Screaming Frog SEO Spider
Das unter SEOs sehr beliebte Crawling Tool Screaming Frog bietet ebenfalls eine Möglichkeit, eine robots.txt-Datei zu testen. Sowohl die in einem System hinterlegte robots.txt als auch eine für den Test angepasste Datei. Das ist sehr praktisch, um mögliche Auswirkungen zu testen bevor Änderungen eingespielt werden. Der große Vorteil ist, Sie können die Auswirkungen der Einträge auf das gesamte System testen und der Screaming Frog kann die ganze Website crawlen und Ihnen einen Report über die gesamte Website erstellen. So sehen Sie auch versehentliche Ausschlüsse oder können Muster entdecken, welche Sie noch vergessen haben.
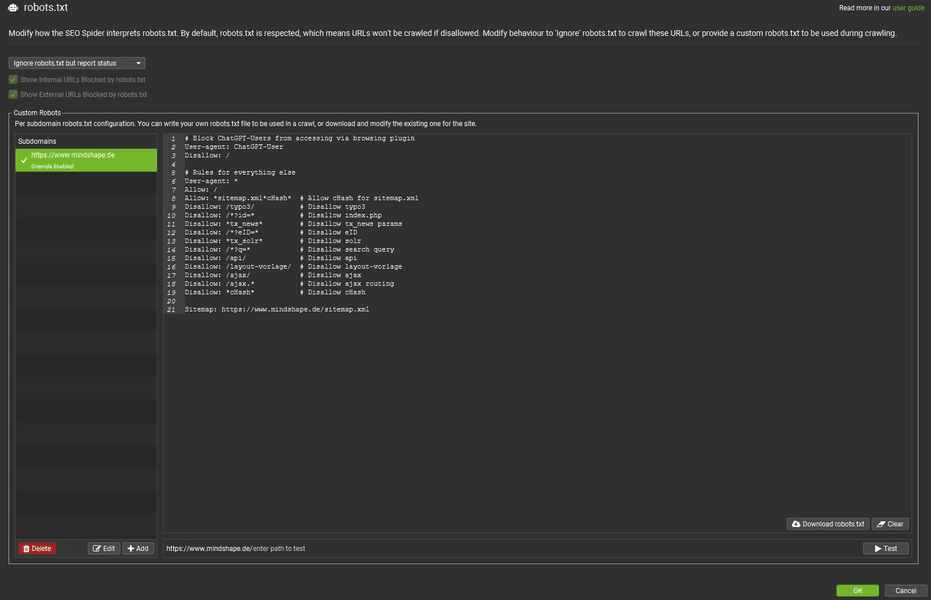
Zu den Einstellungen gelangen Sie über die Menüpunkte „Configuration“ > „robots.txt“. Dort wählen sie zum Testen am besten das Modul „Ignore robots.txt, but report status“. Denn so kann der Crawler alle URLs erfassen und einen möglichen Effekt reporten. Wählen Sie die Einstellung „Respect robots.txt“, so verfolgt der Screaming Frog blockierte Bereiche nicht, hinter denen sich vielleicht aber weitere URLs befinden, welche Sie beim Aufbau Ihrer robots.txt beachten müssen.
Weitere Quellen
Für ganzheitlichen Erfolg im Online Marketing
SEO Consulting
Wir helfen Ihnen dabei, Sichtbarkeit in Suchmaschinen zu erlangen und mehr qualifizierte Besucher:innen auf Ihre Website zu führen. Dafür legen wir uns ins Zeug – mit Leidenschaft, geballtem Know-how und über 19 Jahren Markterfahrung als SEO-Agentur. Bereits seit 2002 unterstützen wir Kund:innen im Bereich Suchmaschinen-Optimierung.
Content-Kreation
Ihr digitaler Erfolg entsteht durch kreative Inhalte, die Ihre Website-Besucher:innen informieren und begeistern. Als erfahrene Agentur für Content-Kreation entwickeln wir eine Strategie für Ihr Content Marketing, die auf Ihr Unternehmen und Ihre Zielgruppen zugeschnitten ist. Im Zentrum stehen die richtigen Inhalte an der richtigen Stelle Ihrer Website.
Webauftritt optimieren
Als zentraler, virtueller Berater entwickeln wir gemeinsam mit Ihnen Ihre performante, individuelle und professionelle Website. Unsere Website Services reichen dabei von der strategischen Konzeption über ein ästhetisches, funktionales UX/UI-Design und die individuelle Entwicklung bis hin zur laufenden technischen Website-Betreuung.




